As a final post, I’m going to summarize what I’ve done for this Dogs vs Cats project. Let’s do it chronologically.
Blog post 1: First results reaching 87% accuracy
To begin with this project, I started by a relatively small network with an architecture inspired from the very classical AlexNet: a stack of convolutional and 2×2 maxpooling layers, followed by a MLP classifier. The size of convolutional filters was decreasing as we go deeper into the network: 9×9, 7×7, 5×5, 3×3… ReLUs for each hidden layers and Softmax for the output layer. This network was taking 100×100 grayscale images as inputs. This post also presents quickly my data augmentation pipeline (rotation + cropping + flipping + resizing) which has never changed. This data augmentation process permitted the network to reach an accuracy equal to 87% (without data augmentation, the same network was reaching an accuracy equal to 78%).
Blog post 2: Adopting the VGG net approach : more layers, smaller filters
The second post starts by a review of the VGGNet paper. The VGGNet approach consists in increasingly significantly the depth, using only 3×3 convolution filters. In my post, I make a comparison between two models with a comparable number of parameters: one network with an architecture inspired by the VGGNet paper, and another one similar to the network from my first post. The VGGNet-like network won the contest easily: 91% vs 86%. In this post, I started using bigger input image : 150×150, and I’ve used this input size until the end.
Note: All the testset scores reported in the first blog posts (from 2 to 7) corresponds to a score obtained on 2500 trainset images (at this time, I was not aware that it is still possible to make a Kaggle submission after the competition’s end).
Blog post 3: Regularization experiments – 7.4% error rate
In this post, I presents some regularization experiments. Dropout on fully connected layers permitted me to improve the accuracy of a network presented in the previous post: 92.6% (+1.1%). I also tried weight decay but it was not helping.
Blog post 4: Adding Batch Normalization – 5.1% error rate
This post starts by a review of the Batch Normalization paper. Batch Normalization is a technique designed to accelerate the training of neural networks by reducing a phenomenon called “Internal Covariate Shift”. It allows the use of higher learning rates, and also acts as a regularizer. After this paper review, I present my experiments when adding Batch Normalization between each layer of my previous network. I verified some claims of the papers: (a) BN accelerates the training: 
Blog post 5: What’s going on inside my CNN ?
In this post, I decided to spend some time evaluating my best model at this time. I started by an analysis of misclassified images. Then, I showed the feature maps obtained when applying the model on a single example. Finaly, I spent some time describing what’s going on when adding a Batch Normalization in terms of activity distribution.
Blog post 6: A scale-invariant approach – 2.5% error rate
This post presents the kind of architecures that have permitted me to reach really nice results: >97%. This architecture is inspired from this paper: Is object localization for free? by M. Oquab and based on the use of a Global Maxpooling Layer. In this post, I show that this architecture makes the network more scale-invariant, and that the Global Maxpooling Layer absorbs a kind of detection operation. I also showed that the network gives more importance to the head of the pet. In this post, I also presents my new testing approach, which requires averaging 12 predictions per image (varying the input size, the model and flipping or not the image).
Blog post 7: Kaggle submission – Models fusion attempt – Adversarial examples
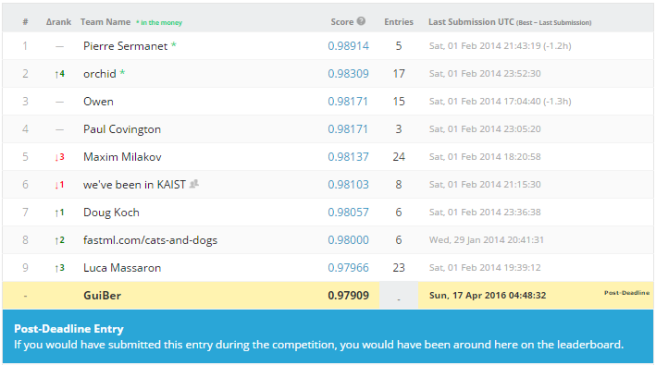
I started this post by showing the Kaggle Testset score (97.51%) obtained by my ensemble of 2 networks presented in the previous post. This score corresponds to my first leaderboard entry. Then, I presented a model fusion attempt: the idea was to concatenate the features outputed by the Global Maxpooling Layer of both models, and give it to a single MLP. This idea has not leaded to higher performance. Finally, I played a bit with adversarial examples (see this paper). In the post, I said that I was working on a way to make my models “robust to adversarial examples by continuously generating adversarial dogs/cats during the training”. It turns out that I’ve never reported my results about that. Let’s do it now: well… it has been a failure… During the training, the network was seeing one batch of “normal” examples, and then one batch containing the corresponding “adversarial examples”. But this approach made the training slower, and at the end, the validationset accuracy was significantly lower (around -1%). But I’ve not played a lot with hyper-parameters for this experiment, so there is maybe a way to make it work.
Blog post 8: Parametric ReLU – 2.1% error rate
In my final post, I describe my experiments when replacing ReLUs by Parametric ReLUs. It improved slightly the Kaggle Testset score: 97.9% (+0.4%). This score corresponds to my second leaderboard entry. Then, as I’ve been asked to clarify some point about my testing approach by classmates, I came back on it. Even if computationally costly, this multi-scale testing approach is one of the main reasons to explain why I got really good results.
Well… Playing with these dogs and cats was fun. If I had more time, I would have enjoyed trying to implement Spatial Transformer Networks, or experimenting Residual Neural Networks. Maybe next time…


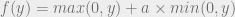
 is a learnable parameter. When
is a learnable parameter. When  , a PReLU becomes a ReLU. PReLU is therefore a generalization of ReLUs. In terms of complexity, it only adds 1 parameter per channel.
, a PReLU becomes a ReLU. PReLU is therefore a generalization of ReLUs. In terms of complexity, it only adds 1 parameter per channel. . Learning curves for each model are displayed in Figure 2 and 3.
. Learning curves for each model are displayed in Figure 2 and 3.