Kaggle Submission:
In my last post, I explained how I managed to reach a testset accuracy equal to 97.5%. Since I was not aware that it is still possible to make a Kaggle submission after the competition deadline, models were trained on 17500 images, validated on 3750 images, and finally tested on 3750 images, with every image taken from the trainset provided on the Kaggle website. Here is the score when evaluating my ensemble of model on the Kaggle Testset:
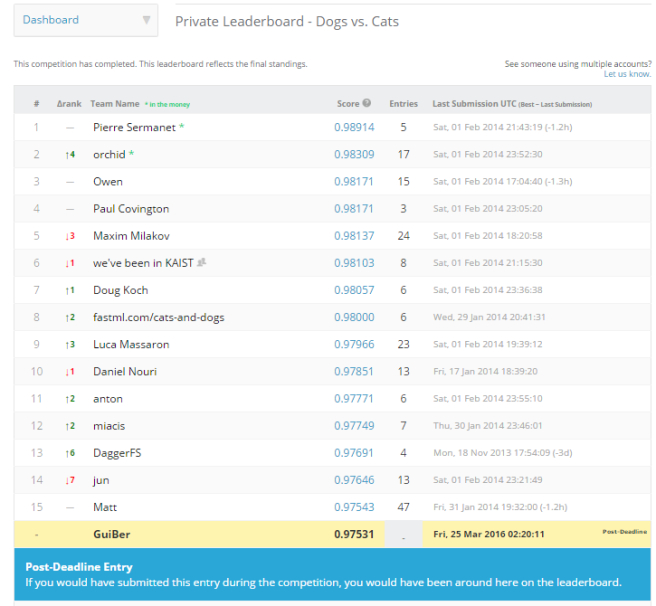
I’ve not re-trained my models recently, so I think it is possible to slightly improve this score by using the entire dataset (25000 images) for training & validation.
Models fusion attempt:
The score presented above has been reached by averaging many predictions for each testset images. Varying the image version (raw or left-right flipped), the image size (150×150, 210×210, and 270×270), and the model (Window46 model, and Window100 model), my testing process is arithmetically averaging 12 predictions per testset image. A simple averaging is probably not the optimal way of fusing predictions. With this idea in mind, I tried to fuse models together: just after the global maxpooling operation, features of both models are concatenated and given to the same fully connected block. Figure 2 illustrates the process:
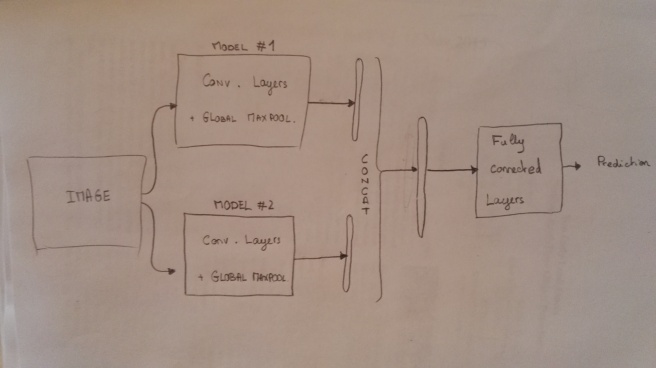
Therefore, my Window46 and Window100 models are now sharing the same fully connected layers. Architecture for FC layers: Concatenated features (dim=384) > 1024 neurons > 512 neurons > 2 neurons.
During the training, Conv. layer weights are loaded from my best models (Window46 and Window100 models) and freezed: only the weights from FC layers are learned. I wanted to fine-tune convolutional weights, but I ran into errors when I tried to train the entire network in a end-to-end fashion…
The fused model gives me the following testset accuracy when testing only on 150×150 images:

Note that there is still an averaging going on: Final prediction = Mean (Prediction (raw) + Prediction (flipped)).
And the accuracy when averaging predictions for 3 sizes (150×150, 210×210, 270×270) is:

So, fusing models together has not permitted to reach a higher score. I see two possible reasons to explain it:
- Since only fully connected layers are learned, the training does not make convolutional layers cooperate. Features given by each convolutional block might contain very redundant information.
- The fused model involves less parameters: instead of having 2 fully connected blocks (one for each model) as it was the case when averaging final predictions given by the 2 distinct models, now there is only one. I could have tried to keep the number of parameters fixed by making the FC block of the fused model deeper or wider.
I’ve not pushed further my fusion experiments. I decided to work on something more intriguing and interesting: adversarial examples.
Adversarial examples:
Adversarial examples have been introduced in this paper ([1] Intriguing properties of neural networks, Szegedy et al, 2014). Citing the abstract, authors have shown that “we can cause the network to misclassify an image by applying a certain hardly perceptible perturbation, which is found by maximizing the network’s prediction error”. See figure 3 for an illustration of adversarial examples obtained for one of my models:
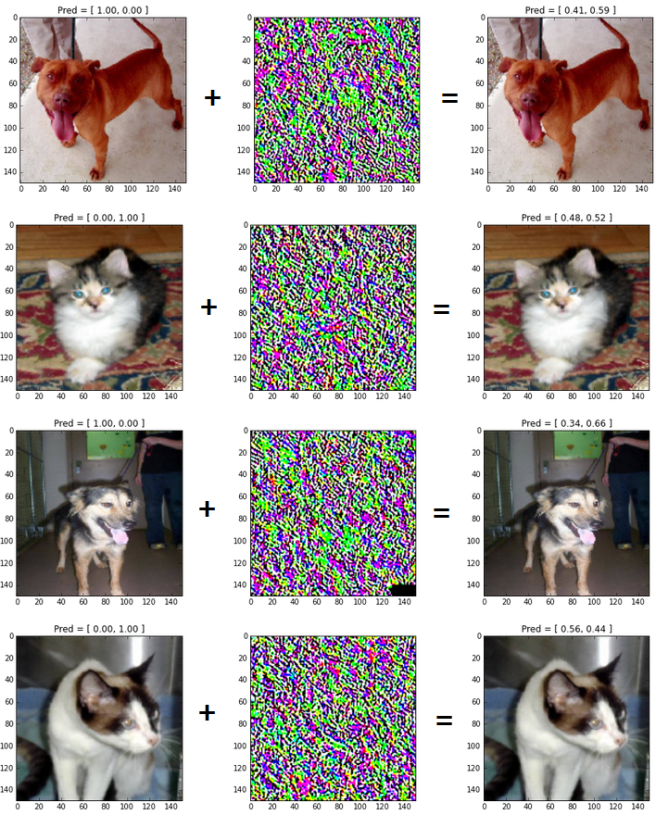
Following the approach from this other paper about adversarial examples ([2] Explaining and Harnessing Adversarial Examples, Goodfellow et al, 2015), the perturbation has been obtained as:

(code available here)
Adversarial examples shows that the network fails in understanding the true underlying concepts of “Dogs” and “Cats” images. I’m actually trying to make the model robust to adversarial examples by continuously generating adversarial dogs/cats during the training, and adding them to the trainset (as it was done in [1]). These experiments will be reported in my next post.

Did you try using something like a max pooling instead of averaging over your ensemble of models ? I think it makes sense to consider that the prediction with the highest confidence is more reliable than an average over predictions?
LikeLiked by 1 person
I just tried and it seems that averaging predictions provides slightly better results (+0.1%) than maxpooling the predictions.
To explain it, you can consider the extreme case where 1 prediction is completely wrong (I’m 95% certain that it is a cat whereas it is a dog-image) but the 11 others are true but less confident (0.5 < p(dog) < 0.95). In this case, the maxpooling operation will keep the wrong prediction. On the contrary, you may get the good answer by averaging predictions.
LikeLike